Social Signals
What 3.4 million articles reveal

Jun

You’ve in all probability seen some model of those three claims:
- Quote-led headlines outperform plain declarative ones by almost 29%.
- Query headlines underperform each, typically by 24%.
- Format drives the outcome: Rewrite a press release as a quote, or add that magic phrase, and it’s best to anticipate an actual carry.
We examined all three in opposition to 1,674,518 English editorial articles and 1,690,295 French articles from the 1492.imaginative and prescient Uncover corpus (November 2025 to Could 2026): about 3.4 million editorial articles with not less than one seize throughout our fleet.
They share a deeper flaw than any of their numbers.
All three deal with headline format as a trigger — a lever you pull to realize visibility. However the knowledge exhibits, layer after layer, {that a} format’s measured impact is sort of totally a proxy for one thing else: which writer used it, for which viewers, and on which Uncover floor.
The headline is a symptom of these decisions, not an impartial driver.
The clearest demonstration is Simpson’s paradox. When you see it, you discover it all through the dataset.
A word on what we measure
Our metric isn’t clicks from Uncover; no third celebration has that knowledge. It’s hits per article: how usually an article seems throughout the 1492.imaginative and prescient fleet we observe, a proxy for visibility.
The corpus is restricted to editorial articles. YouTube and X are excluded as a result of their headlines observe totally different conventions. We’ll return to each on the finish—they sharpen the purpose greater than anything.
A phrase on why the amount issues: your entire argument relies on having the ability to slice 3.4 million articles by writer, Uncover floor, matter, and language whereas nonetheless retaining sufficient knowledge in every section for significant comparisons. That’s the distinction between a quantity and an perception — and between an actual format impact and a statistical mirage.
The quantity is actual, on the mistaken altitude
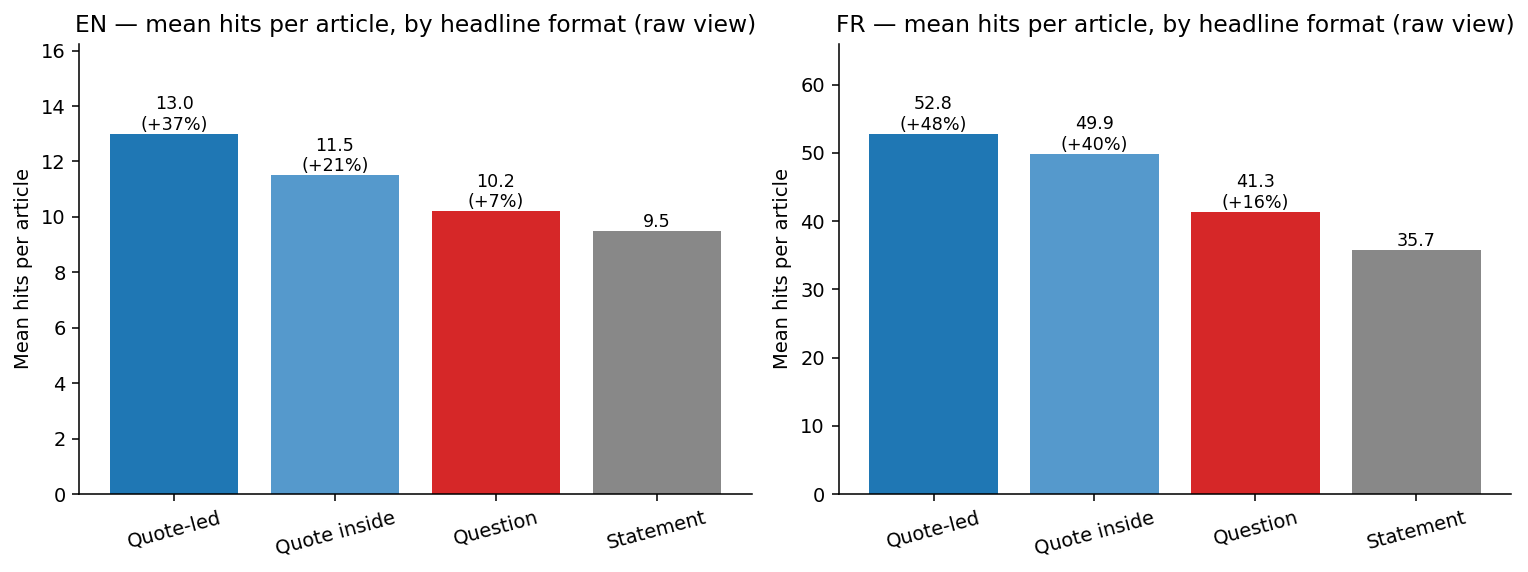
Pool all publishers collectively, and a clear gradient emerges: quote-led headlines on the prime, statements on the backside.
| Lang | Format | Articles | Imply hits | Median | vs assertion |
|---|---|---|---|---|---|
| EN | Quote-led | 38,044 | 13.0 | 4 | +37% |
| EN | Quote inside | 75,463 | 11.5 | 4 | +21% |
| EN | Query | 53,081 | 10.2 | 4 | +7% |
| EN | Assertion | 1,674,518 | 9.5 | 3 | baseline |
| FR | Quote-led | 179,472 | 52.8 | 13 | +48% |
| FR | Quote inside | 223,052 | 49.9 | 12 | +40% |
| FR | Query | 103,117 | 41.3 | 11 | +16% |
| FR | Assertion | 1,690,295 | 35.7 | 9 | baseline |
The generally cited +29% is conservative for pure editorial articles: quote-led headlines present a +37% carry in English and +48% in French. Questions, removed from underperforming, additionally outperform statements (+7% EN, +16% FR).
At this degree of aggregation, declare 1 seems understated and declare 2 seems plainly mistaken.
That is the extent of aggregation the place most headline recommendation is born. Maintain onto that +37% determine — the remainder of this piece is about what it’s truly measuring.
Hidden variable 1: which writer
The mixture can’t reply an important objection by itself: the publishers that use quotes aren’t the identical publishers that don’t.
Movie star media, regional dailies, and buzz-driven websites lean closely on quotes and earn extra Uncover hits per article no matter headline format. Pure-play publishers, wire companies, and utility-focused websites favor declarative headlines and have a tendency to take a seat decrease.
The uncooked comparability, then, isn’t quote versus assertion. It’s one writer inhabitants versus one other.
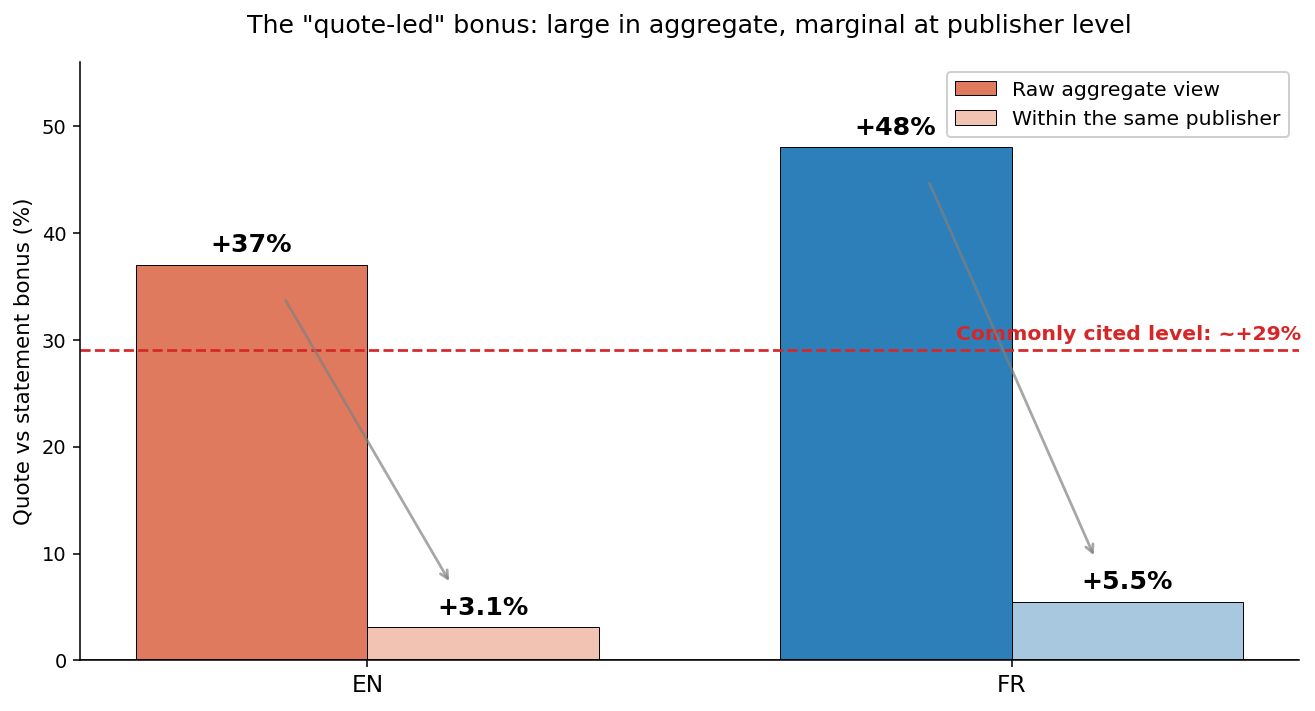
This can be a textbook Simpson’s paradox: a powerful development within the combination that weakens, disappears, or reverses when you section by group.
To get anyplace close to the impact of headline format itself, the grouping variable must be the writer.
So make every writer its personal baseline: evaluate quote versus assertion inside the identical web site, holding viewers and matter combine fixed.
Throughout 324 English and 439 French publishers with sufficient of each codecs — not less than 50 quote and 200 assertion articles every:

| Lang | Publishers | Quote wins (median web site) | Quote wins (imply web site) | Median within-publisher Δ |
|---|---|---|---|---|
| EN | 324 | 31.5% | 55.9% | +3.1% |
| FR | 439 | 47.6% | 57.4% | +5.5% |
In English, statements outperform quotes at 68% of publishers by the median; quote-led headlines damage extra usually than they assist. In French, the result’s near a coin flip.
That leaves the underlying format impact at roughly +3% to +5%—about 5 to 9 instances smaller than the mixture determine.
(The imply is increased than the median as a result of a minority of publishers see massive positive aspects from quotes. The median is the extra dependable measure of the everyday writer.)
Cease right here and the lesson seems like “section your knowledge.” However the collapse factors to one thing bigger.
If three-quarters of a +37% impact was actually a writer impact, the plain subsequent query is: what else is the headline metric standing in for?
The remainder of this text is a tour of these hidden variables. And by this level, the reply to assert 3 is already coming into view: the format itself isn’t the motive force.
The identical substitution, in reverse: questions

The standard recommendation says questions underperform by roughly 24%. The mixture view of our knowledge says the other: questions outperform statements (+7% EN, +16% FR).
Each conclusions are mistaken for a similar cause. Query headlines are disproportionately utilized by high-engagement publishers, which inflates their combination efficiency.
Inside publishers, the image settles.
In English, query headlines present a modest actual underperformance (-3.7%), profitable at solely 29.3% of websites. In French, the impact is actually impartial (-0.5%), with questions outperforming at 46.2% of websites.
The standard recommendation will get the path roughly proper in English and impartial in French, however its traditional magnitude is about sixfold too massive.
The query mark isn’t the trigger. The form of writer utilizing it’s. Identical hidden variable, reverse signal.
The impact gained’t even maintain nonetheless

Even that modest within-publisher impact drifts from month to month.
In English, it peaks at +2.5% and turns unfavorable in March 2026, whereas statements outperform questions at 55% to 60% of websites every month. In French, it ranges from +3% to +12% — strongest in December and February, weakest in March — with no clear development.
A real causal lever shouldn’t wobble like this. A correlation tied to a shifting content material combine ought to.
Hidden variable 2: Which viewers

The +3-5% common hides a pointy, constant cut up. In English:
- Gainers: Worldwide common information (BBC +85%, Forbes +46%, CBS Information +43%, Boston Globe), Yahoo aggregators, mass-market magazines (Parade, Good Housekeeping), Gizmodo.
- Losers: Specialist sport (RugbyPass, Planet F1, ThisIsAnfield), leisure (IMDb, TVInsider, Folks), and factual-leaning dailies (Customary, Washington Put up).

French knowledge follows the identical sample in a special market.
- Gainers: Regional newspapers (La Dépêche, La Montagne, L’Écho Républicain) and general-interest magazines (Grazia).
- Losers: Specialist sports activities retailers (Foot Nationwide, le10sport, MadeInFoot), expertise publishers (Les Numériques), and service-oriented titles (Journal des Femmes, Femme Actuelle).
The sample is editorial, not algorithmic. Quotes are inclined to work the place the viewers comes for commentary, response, and framing, and fail the place the viewers comes for information.
A writer constructed round “what somebody mentioned” advantages from a quoted headline. One constructed round “what simply occurred” normally doesn’t.
The convergence between English and French is the giveaway. This isn’t a language impact; it’s a reader-intent impact.
What seems like a headline-format impact is, on this case, an viewers impact sporting the garments of a headline.
Hidden variable 3: Which Uncover floor
Uncover isn’t a single feed. It’s a collection of pipelines, every deciding on articles in numerous methods:
- Editorial curation (
moonstone,mustntmiss). - The primary topic-personalization engine (
aura). - Associated-reading context (
paginationpanoptic,content material). - Similarity-based suggestion (
relatedcontentruby,userpersonascontent).
First, rule out the plain various rationalization. Are quote-led articles merely being routed to higher-value Uncover surfaces, making the obvious bonus a placement impact slightly than a headline impact?
The info says no.
Evaluating the place quote and assertion articles truly seem, the distributions are almost similar. In English, the biggest variations are small: content material.f (+2.2 proportion factors), aura.f (-1.9), and moonstone.f (+0.6).
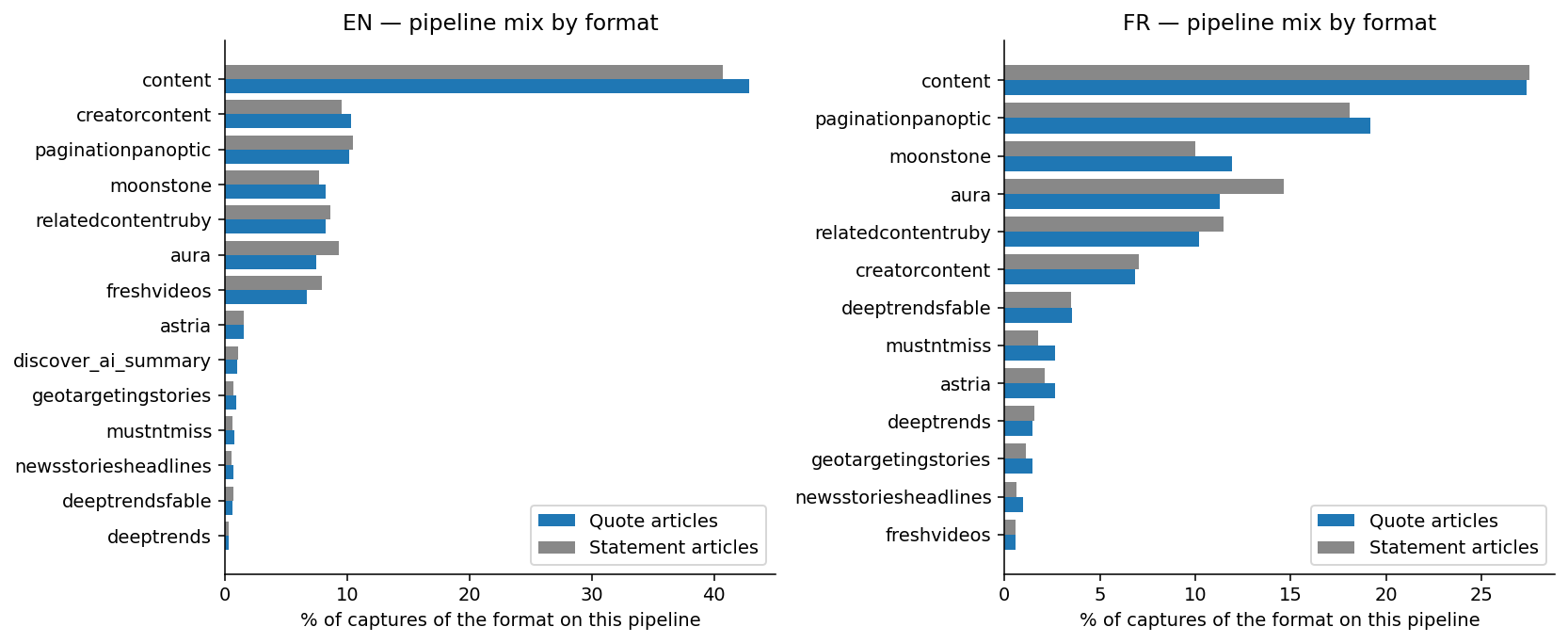
The bonus isn’t about placement: quotes and statements seem on the identical surfaces in the identical proportions. It’s about depth — how every format performs as soon as it’s on a floor. There, the general +3% to five% breaks into a variety: from +22% to -14% in EN and from +25% to -12% in FR.

Grouped into useful households, the sample is readable:
| Pipeline household | EN | FR |
|---|---|---|
| Editorial curation (moonstone, mustntmiss, astria, information…) | +3.4% | +9.7% |
| Associated studying / context (paginationpanoptic, content material…) | +2.0% | +6.7% |
| Developments / freshness (deeptrends, freshvideos…) | +4.4% | +2.3% |
Foremost personalization (aura) | +0.6% | +1.8% |
| Similarity-based suggestion (relatedcontentruby, userpersonas…) | -1.6% | -1.9% |
Quote-led headlines win the place a number of headlines compete for consideration without delay — curation carousels, information clusters, and different surfaces the place the title carries a social sign: somebody mentioned this. They lose on similarity-based suggestions, the place the floor sells continuity (“since you learn X, you’ll learn Y”) and a quote disrupts the topic-clear promise with an out-of-context quotation.
The biggest pipeline by quantity, Aura, ranks on matter affinity and barely reacts to format in any respect, with positive aspects of simply +0.6% to +1.8%.
Why is the web impact so small?
A single quote-led FR article doesn’t get one quantity; it will get a mix:
- +10 to +25% on its curation share (moonstone, mustntmiss, astria)
- ~0% on its aura share, the biggest slice of quantity
- -3% on its relatedcontentruby share (≈ 10% of captures)
- -2 to -6% on buying/viewer-related surfaces
Combine these and also you land at +4% to +7% web. The curatorial positive aspects are actual however partly offset by suggestion losses, which is why the mixture is nowhere close to +29%. The identical format is each an asset and a legal responsibility, relying totally on the floor serving it.
And +4–7% overstates how a lot the format itself issues as a result of every pipeline’s rating is a compound of alerts unrelated to the title: engagement, scroll depth, matter affinity, E-E-A-T, entities, studying historical past, location, timing, and prior interactions.
A quote within the headline is, at finest, one weak sign competing with all of these. Lengthy earlier than an article reaches a feed, it’s largely swamped by all the things else.
Questions by pipeline, identical story sharper

These are within-publisher medians (every writer in opposition to itself), in order that they aren’t a crude artifact of FR utilizing extra questions. The format follows the identical pipeline logic as quotes, however in a extra polarized kind:
- FR curation leans constructive on questions; EN curation leans unfavorable.
astria.f, the identical pipeline in each languages, runs +9% in FR and -1% in EN; FRmustntmiss.fis +14%, ENmoonstone.fis -13%. - Similarity-based suggestion penalizes questions in all places, tougher than quotes:
relatedcontentruby.fFR -11.5% (306 publishers), EN -6.1% (119);itemitemcollaborativefiltering.fFR -14.5%. aurastays impartial in each (+3.5% FR, -0.6% EN).
Two caveats level in the identical path:
- A fleet-capture metric can’t distinguish an algorithmic penalty from an audience-eviction impact: readers see a query mark, determine “not now,” and scroll previous. The truth that relatedcontentruby — which serves already-engaged readers — penalizes questions this closely factors to a behavioral sign, not simply rating.
- Inside-publisher pairing controls for every writer in opposition to itself, however the median continues to be computed throughout a special set of publishers in FR and EN, on partly totally different surfaces. So “FR rewards questions, EN doesn’t” describes the publishers and matters occupying every cell, not an inherent property of the language or the query mark. It’s one other hidden variable mistaken for a format impact.
Hidden variable 4: Which editor, and which judgment
Even the trustworthy +3% to five% comes with a caveat that outweighs its dimension. When a writer writes a headline as a quote, they select the most effective accessible quote for that story. So the within-publisher determine compares the most effective quote an editor chosen with the typical of all that writer’s statements, not the identical article written two methods.
It’s the subject-line A/B testing drawback: a superb various beats a nasty one, however the common various doesn’t. Convert each headline to quote-led and also you’d be writing common quotes, so a lot of the achieve would disappear. The +3–5% is an higher certain on a selective follow, not the return from a blanket rule.
That’s the ultimate cause “do it in all places” fails:
- Not each article has a quote. A sports activities outcome, a press launch, a market evaluation, a product take a look at: forcing one means fabricating it.
- The editor-selection bias above: The measured bonus is the most effective quote chosen, not a property of the format.
- Suggestion pipelines are long-tail levers.
relatedcontentrubyand pals are how an article redeploys after its preliminary peak, the principle mechanism for extending Uncover lifetime. Optimizing the headline for the curation peak whereas breaking the promise on these surfaces can web unfavorable. - The biggest pipeline barely reacts.
aurais 11% to fifteen% of FR captures and seven% to 9% of EN, with a +0.6% to 1.8% quote impact. A common quote rule optimizes secondary surfaces whereas ignoring that the largest one runs on matter affinity.
The clincher: the identical format, reverse which means

We excluded YouTube and X from the principle corpus, however their outcomes are the clearest proof of the thesis. The identical quote-led format produces reverse results relying totally on what the title is attempting to do.
| Area | Lang | Quote articles | Assertion | Imply hits quote | Imply hits stmt | Δ |
|---|---|---|---|---|---|---|
| YouTube | EN | 43,476 | 734,986 | 11.6 | 10.2 | +14% |
| YouTube | FR | 16,509 | 93,912 | 59.0 | 29.1 | +103% |
| x.com | EN | 34,156 | 268,175 | 5.2 | 4.9 | +6% |
| x.com | FR | 32,201 | 114,914 | 21.4 | 24.6 | -13% |
On YouTube, the title is successfully a textual content thumbnail that has seconds to create curiosity. A quote serves as a content material promise — “right here’s the road price listening to” — which helps clarify the +103% end in French. On X, the title is the publish itself, and a detected quote normally signifies that somebody is repeating or responding to a different individual’s phrases, diluting the unique message. That correlates with a -13% outcome.
Identical characters. Identical regex. Reverse final result. The format didn’t change; the job it was doing did.
(Methodological footnote: a naive audit that folded YouTube into the editorial corpus would inflate the general quote bonus by 20–30 factors, whereas one which folded in X would dilute it. Any critical headline research has to isolate editorial articles earlier than measuring headline results.)
The headline was by no means the variable
Put the layers collectively. Three-quarters of the +37% uncooked bonus was defined by writer variations. What remained cut up once more by viewers, then by Uncover floor, then by which quote the editor chosen, and eventually reversed totally when the title served a special perform on one other platform. At each step, eradicating context shrank or flipped the obvious format impact.
There’s no clear residue on the backside the place the headline acts independently. The impact is inseparable from the context that creates it.
That’s not a measurement failure; it’s the discovering. We simply noticed the mechanism. Headline format is one weak sign amongst many stronger ones, all transferring by pipelines that usually pull in reverse instructions.
The consequence is the purpose. An article’s visibility is the operating rating of that whole contest, not the decision of any headline rule. A quantity measured throughout publishers is downstream of all the things that travels with the format: who printed it, what matter it covers, what the viewers expects, the newsroom’s type and habits, and the conventions of the language itself.
So when an combination stories “+29% for quotes,” it isn’t isolating the citation marks. It’s measuring a correlation with that complete bundle of things and quietly relabeling it as causation.
None of this implies combination knowledge is the enemy. Every little thing above comes from combination knowledge, simply analyzed on the proper degree.
The lure is narrower: treating a single beauty variable, averaged throughout publishers that don’t belong in the identical class, as a causal lever.
The identical index that exposes that mistake additionally reveals the alerts that genuinely drive Uncover: which matters a writer wins on, which entities are accelerating, who dominates a given floor, and what’s trending earlier than it peaks. These alerts aren’t beauty, and so they aren’t drowned out by stronger forces. They’re the underlying demand that headline format solely weakly approximates.
The lesson isn’t “ignore the information.” It’s “cease averaging the mistaken variable throughout the mistaken inhabitants.”
For this reason no cross-publisher common, corrected or not, converts right into a rule to your web site:
- Visibility isn’t site visitors. Two websites can earn similar Uncover visibility on the identical article and see very totally different CTRs as a result of their audiences click on for various causes.
- No two audiences are the identical. A quote that reads as insider commentary to {a magazine} reader might learn as imprecise or irrelevant to somebody scanning sports activities scores.
- A cross-publisher common of 1 beauty function is the typical of audiences you don’t have. Section by your viewers, your matters, and your surfaces, and it turns into info once more.
The one take a look at that solutions your query is the one you run by yourself web site, with your personal viewers. Know who you’re writing for, then measure them. Slice the information by your viewers, your matters, and your surfaces — not by a single quantity averaged throughout everybody.
So what in regards to the three claims?
Every is actual as a correlation and ineffective as a trigger:
- “Quotes beat statements by ~29%”: True in combination — bigger than +29%, in reality — however largely defined by writer variations. On the writer degree, the residue is +3% to five%, and even that compares the most effective quote an editor chosen in opposition to the typical of all statements, not the format itself.
- “Questions underperform”: Directionally true in EN, impartial in FR, however the magnitude is about 6x too massive. The precise impact is roughly -4% in EN and ~0% in FR.
- “The format itself is the motive force”: The declare the dataset refutes. The identical article from the identical writer, mechanically rewritten as a quote, wouldn’t achieve the mixture impact.
The trustworthy model, if you’d like one sentence to maintain:
A quote-led headline can earn roughly +3% to 7% further Uncover visibility for audiences that worth commentary and framing (common information, magazines, regional press), particularly on curation surfaces, and lose for factual audiences (sports activities, tech, utility) and on similarity-based suggestion surfaces. There may be no common achieve from citation marks; the favored ~+29% determine overstates the format impact by roughly an order of magnitude. The helpful query isn’t “Ought to I take advantage of a quote?” however “Who am I writing for, and which Uncover floor drives my site visitors?” The one place to reply that’s with your personal web site, not anybody else’s common.
Methodology
- Knowledge and interval: 1,674,518 EN and 1,690,295 FR editorial articles with Uncover visibility from 1492.imaginative and prescient proprietary knowledge, collected between 2025-11-01 and 2026-05-19. Editorial articles solely; excludes adverts, movies, AI Overviews, and showcases. Area exclusions: x.com, twitter.com, m.twitter.com, youtube.com, www.youtube.com, and m.youtube.com (reported individually above).
- Headline format detection (regex): Quote-led: title begins with a multi-word quoted phrase (“…”, «…», ‘…’, or ‘X…’:). Quote inside: a quoted phrase seems however not at first. Query: ends with ?. Assertion: all the things else. Titles below 20 or over 300 characters are excluded. Detection intentionally errs towards false negatives within the quote bucket, biasing in opposition to discovering a quote impact, so the +3–5% is conservative.
- Three layers of research: (1) Uncooked combination: all publishers pooled, producing +37% / +48%. (2) Inside-publisher: quote vs. assertion inside every writer with ≥50 quote and ≥200 assertion articles; we report the share of publishers favoring quotes and the median per-publisher Δ. This neutralizes publisher-mix bias. (3) Month-to-month evolution: the identical pairing, recomputed month-to-month with relaxed thresholds (≥10 quote, ≥40 assertion).
- Pipeline layer: Captures come from 1492.imaginative and prescient proprietary knowledge, with every row representing one seize on a particular pipeline. For every (pipeline, format, writer), captures per article = pipeline captures ÷ distinct articles. Inside-publisher pairing contains publishers with ≥20 quote (or query) and ≥60 assertion articles on that pipeline. A pipeline is proven provided that ≥5 publishers qualify. Pipeline households are an empirical grouping (editorial curation, associated studying, traits, similarity-based suggestion, and major personalization) that displays how every floor behaves.
- Metric: A “hit” is one seize of an article on Uncover by the 1492.imaginative and prescient gadget fleet. It’s a visibility proxy, not a go to.
- Identified limitations: (1) No site visitors knowledge: the metric is Uncover visibility, not clicks, so a format might have an effect on CTR independently with out showing right here. (2) Regex detection misses edge circumstances and is biased towards under-counting quotes. (3) Inside-publisher results evaluate the most effective quote an editor chosen in opposition to the typical assertion, not the counterfactual of creating each headline quote-led. (4) Some unfavorable pipelines have small writer samples (<10); the constant path issues greater than any particular person magnitude.
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search neighborhood. Our contributors work below the oversight of the editorial staff and contributions are checked for high quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not requested to make any direct or oblique mentions of Semrush. The opinions they specific are their very own.
#million #articles #reveal